在CrunchyData担任解决方案架构师的角色中,我帮助客户使用CrunchyPostgresforKubernetes(CPK)快速上手。在Kubernetes中安装和管理Postgres集群从未如此简单。然而,有时事情不会按计划进行,我注意到一些Kubernetes安装可能出现问题的主要领域。今天,我想逐步介绍一些人们在尝试在Kubernetes中运行Postgres时经常遇到的常见问题,并提供一些基本的故障排除思路以便入门。当然,您的问题可能不在这里,但如果您只是想诊断安装失败或群集故障,这是我首选的入门故障排除清单。

让我们从对事物是如何安装以及由谁安装的基本理解开始。您可以利用这些知识来确定在安装过程中未出现您期望的内容时首先查看何处。
自定义资源定义(CRD):CPKOperator需要一个自定义资源定义(CRD)。每个Operator可以拥有多个CRD。我们最新的Operator版本,5.5,包含了3个CRD示例,其中之一是_。用户将所有CRD文件应用于Kubernetes集群。在安装Operator之前,必须先安装CRD。
Operator:用户通过应用文件来安装CPKOperator,该文件描述了一种kind:Deployment的Kubernetes对象。这将创建Deployment,而Deployment又会创建OperatorPod。Operator本身是运行在Pod中的容器。
PostgresCluster:CPKPostgresCluster通常由用户应用包含描述的文件创建,该文件描述了一种kind:PostgresCluster的Kubernetes对象。
Pods:StatefulSets和Deployments创建它们所描述的各个Pods。Operator为每个PostgresPod和pgBackRestrepo主机Pod(如果适用)创建一个StatefulSet。还会为pgBouncerPods(如果适用)创建Deployments。如果缺少某个Pod,请查看拥有该Pod的Deployment或StatefulSet的描述。如果缺少Deployment或StatefulSet,通常可以在CPKOperator日志中找到原因。
镜像拉取接下来,让我们看一下镜像拉取问题。有两个主要原因会导致镜像拉取错误。1-您没有权限连接到镜像仓库或拉取所请求的镜像。或者2-请求的镜像不在镜像仓库中。
权限示例尝试部署CPKOperator。
kubectlapply-npostgres-operator-kinstall/default--server-side
我发现出现了ImagePullBackOff错误。
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEpgo-5694b9545c-ggz7g0/1ImagePullBackOff027s
在Kubernetes中,当Pod无法启动时,首先要做的是运行describe命令查看Pod的详细信息,尤其是输出底部的事件。
kubectl-npostgres-operatordescribepodpgo-5694b9545c-ggz7gEvents:TypeReasonAgeFromMessage-------------------------NormalPulling6m9skubeletPullingimage"/crunchydata/postgres-operator:"WarningFailed6m9skubeletFailedtopullimage"/crunchydata/postgres-operator:":rpcerror:code=Unknowndesc=failedtopullandunpackimage"/crunchydata/postgres-operator:":failedtoresolvereference"/crunchydata/postgres-operator:":failedtoauthorize:failedtofetchanonymoustoken:unexpectedstatusfromGETrequestto;service=crunchy-container-registry:403Forbidden
查看事件,我们发现尝试从CrunchyData镜像仓库拉取crunchydata/postgres-operator:。在下一个事件条目中看到:403Forbidden。这意味着我们没有权限从此镜像仓库拉取此Pod。
添加拉取凭据为了解决问题,我们将创建一个拉取凭据并将其添加到deployment中。您可以在CPK文档中找到有关为私有镜像仓库创建拉取凭据的更多信息。
按照文档创建了镜像拉取凭据并将其添加到deployment中。我们应用了这个更改并删除了失败的Pod。现在我们看到Pod被重新创建,并且成功拉取了镜像。
kubectlapply-npostgres-operator-kinstall/default--server-sidekubectl-npostgres-operatordeletepodpgo-5694b9545c-xnpjgpod"pgo-5694b9545c-xnpjg"deletedkubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEpgo-5694b9545c-xnpjg1/1Running023s镜像不在镜像仓库中的示例
我们再次尝试部署Operator,发现出现了ImagePullBackOff错误。
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEpgo-6bfc9554b7-6h4jd0/1ImagePullBackOff022s
就像之前一样,我们将describePod并查看事件以确定发生这种情况的原因:
kubectl-npostgres-operatordescribepodpgo-6bfc9554b7-6h4jdEvents:TypeReasonAgeFromMessage-------------------------NormalPulling4m30skubeletPullingimage"/crunchydata/postgres-operator:"WarningFailed4m30skubeletFailedtopullimage"/crunchydata/postgres-operator:":rpcerror:code=NotFounddesc=failedtopullandunpackimage"/crunchydata/postgres-operator:":failedtoresolvereference"/crunchydata/postgres-operator:":/crunchydata/postgres-operator::notfound
这次我们尝试从CrunchyData镜像仓库拉取crunchydata/postgres-operator:镜像。然而,未找到该镜像。仔细检查文件中列出的镜像后,我们发现有一个拼写错误。我们的标签应为,而不是。
images:-name:postgres-operatornewName:/crunchydata/postgres-operatornewTag:更改标签名
我们对文件进行了更正并应用了更改。Pod将自动使用正确的镜像标签重新创建。
kubectlapply-npostgres-operator-kinstall/default--server-sidekubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEpgo-6bfc9554b7-6h4jd1/1Running096s
通过使用Kubernetes的describepod功能,我们能够查看我们为何遇到镜像拉取错误,并轻松纠正它们。
资源分配在排除失败的Kubernetes安装问题时,另一个重要的地方是查看资源分配,确保Pod具有必要的CPU和内存。我在安装时经常看到的最常见问题包括:
请求超过了可用的Kubernetes节点上的资源。
资源请求不足以支持Pod中运行的容器的正常操作。
资源请求超出可用范围在这个文件中,我们为我们的PostgresPod设置了一些资源请求和限制。我们请求了5个CPU,并设置了每个PostgresPod的CPU限制为10个。
instances:-name:pgha1replicas:2resources:limits:cpu:10000mmemory:256Mirequests:cpu:5000mmemory:100Mi
当我们创建Postgres集群并查看Pod时,我们发现它们处于挂起状态。
ku/hippo-hacreated
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-pgbouncer-7c467748d-tl4pn2/2Running0103shippo-ha-pgbouncer-7c467748d-v6s4d2/2Running0103shippo-ha-pgha1-bzrb-00/5Ping0103shippo-ha-pgha1-z7nl-00/5Ping0103shippo-ha-repo-host-02/2Running0103spgo-6ccdb8b5b-m2zsc1/1Running048m
让我们describe其中一个挂起的Pod并查看事件:
kubectl-npostgres-operatordescribepodhippo-ha-pgha1-bzrb-0Name:hippo-ha-pgha1-bzrb-0Namespace:postgres-operatorEvents:TypeReasonAgeFromMessage-------------------------WarningFailedScheduling3m41s(x2over3m43s)default-scheduler0/2nodesareavailable:2:0/2nodesareavailable:2Nopreemptionvictimsfoundforincomingpod..
我们注意到可用的CPU不足以满足我们的请求。因此,我们减少了资源请求和限制,然后再次尝试。
instances:-name:pgha1replicas:2resources:limits:cpu:1000mmemory:256Mirequests:cpu:500mmemory:100Mi
ku/hippo-hacreated
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-backup-jb8t-tgdtx1/1Running013shippo-ha-pgbouncer-7c467748d-s8wq62/2Running034shippo-ha-pgbouncer-7c467748d-zhcmf2/2Running034shippo-ha-pgha1-hmrq-05/5Running035shippo-ha-pgha1-xxtf-05/5Running035shippo-ha-repo-host-02/2Running035spgo-6ccdb8b5b-m2zsc1/1Running0124m
现在我们看到所有的Pod都按预期运行。
资源Request不足如果我们没有分配足够的资源会发生什么呢?在这里,我们将CPUrequest和limit设置得非常低。我们请求5mCPU,并将每个PostgresPod的限制设置为10mCPU。
instances:-name:pgha1replicas:2resources:limits:cpu:10mmemory:256Mirequests:cpu:5mmemory:100Mi
ku/hippo-hacreated
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-pgbouncer-7c467748d-hnf5k2/2Running093shippo-ha-pgbouncer-7c467748d-q28t92/2Running093shippo-ha-pgha1-r2qs-04/5Running2(11sago)93shippo-ha-pgha1-x2ft-04/5Running2(8sago)93shippo-ha-repo-host-02/2Running093spgo-6ccdb8b5b-m2zsc1/1Running0136m
我们注意到我们的PostgresPod只显示了4/5个容器正在运行,且在创建90秒后已经重新启动了两次。这清楚地表明出现了问题。让我们查看Postgres容器的日志,了解发生了什么。
kubectl-npostgres-operatorlogshippo-ha-pgha1-r2qs-0-cdatabase
我们没有得到任何日志。这表明Postgres容器没有启动。现在我们将调整CPUrequest和limit为更合理的值,然后再次尝试。通常我不会低于500m。
instances:-name:pgha1replicas:2resources:limits:cpu:1000mmemory:256Mirequests:cpu:500mmemory:100Mi
ku/hippo-hacreated
现在我们看到我们的集群正常运行,所有预期的容器都在运行。
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-backup-pv9n-tr7mh1/1Running06shippo-ha-pgbouncer-7c467748d-45jj92/2Running033shippo-ha-pgbouncer-7c467748d-lqfz22/2Running033shippo-ha-pgha1-8kh2-05/5Running034shippo-ha-pgha1-v4t5-05/5Running034shippo-ha-repo-host-02/2Running033spgo-6ccdb8b5b-m2zsc1/1Running0147m存储分配
最后,让我们看一下在为我们的pods分配存储时可能遇到的一些常见问题。关于在安装时分配存储的问题,有一些最常见的问题:
不正确的资源请求
不受支持的存储类
不正确的资源请求示例这是我们要为中的Postgres集群pods分配的存储的示例:
dataVolumeClaimSpec:accessModes:-'ReadWriteOnce'resources:requests:storage:1GB
当我们尝试应用清单时,我们在命令行上看到了这个输出:
"1GB"的值是无效的。错误消息告诉您错误在清单的[0].部分。消息甚至提供了用于验证的正则表达式。
我们输入有效值1Gi后,成功部署了我们的Postgres集群。请记住,千兆字节必须用Gi描述,而兆字节则用Mi。有关更多语法细节,请参阅Kubernetes文档。
dataVolumeClaimSpec:accessModes:-'ReadWriteOnce'resources:requests:storage:1Giaffinity:
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-backup-ngg5-56z7z1/1Running010shippo-ha-pgbouncer-7c467748d-4q8872/2Running035shippo-ha-pgbouncer-7c467748d-lc2sr2/2Running035shippo-ha-pgha1-w9vc-05/5Running035shippo-ha-pgha1-zhx8-05/5Running035shippo-ha-repo-host-02/2Running035spgo-6ccdb8b5b-vzzkp1/1Running012m不正确的存储类名示例
我们想要为我们的Postgres集群pods指定一个特定的存储类:
dataVolumeClaimSpec:storageClassName:fooaccessModes:-'ReadWriteOnce'resources:requests:storage:1Gi
当我们应用清单时,我们发现我们的Postgrespods被卡在"ping"状态。
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-pgbouncer-7c467748d-jxxpf2/2Running03m42shippo-ha-pgbouncer-7c467748d-wdtvq2/2Running03m42shippo-ha-pgha1-79gr-00/5Ping03m42shippo-ha-pgha1-xv2t-00/5Ping03m42shippo-ha-repo-host-02/2Running03m42spgo-6ccdb8b5b-vzzkp1/1Running024m
此时我们不清楚为什么pods处于ping状态。让我们describe其中一个并查看事件,看看是否能获取更多信息。
kubectl-npostgres-operatordescribepodhippo-ha-pgha1-79gr-0Name:hippo-ha-pgha1-79gr-0Namespace:postgres-operatorEvents:TypeReasonAgeFromMessage-------------------------NormalNotTriggerScaleUp31s(x32over5m34s)cluster-autoscalerpoddidn'ttriggerscale-up:WarningFailedScheduling13s(x6over5m36s)default-scheduler0/2nodesareavailable::0/2nodesareavailable:2Preemptionisnothelpfulforscheduling..
在describe的事件中,我们看到pod具有未绑定的即时PersistentVolumeClaims。这是什么意思?这意味着Kubernetes无法满足我们的存储需求,因此它保持未绑定状态。如果我们检查dataVolumeClaimSpec,我们看到我们设置了三个特定的值:
dataVolumeClaimSpec:storageClassName:fooaccessModes:-'ReadWriteOnce'resources:requests:storage:1Gi
我们查看Kubernetes提供程序中可用的存储类。在这种情况下,我们正在部署在GKE上。我们看到我们有3个可用的存储类:
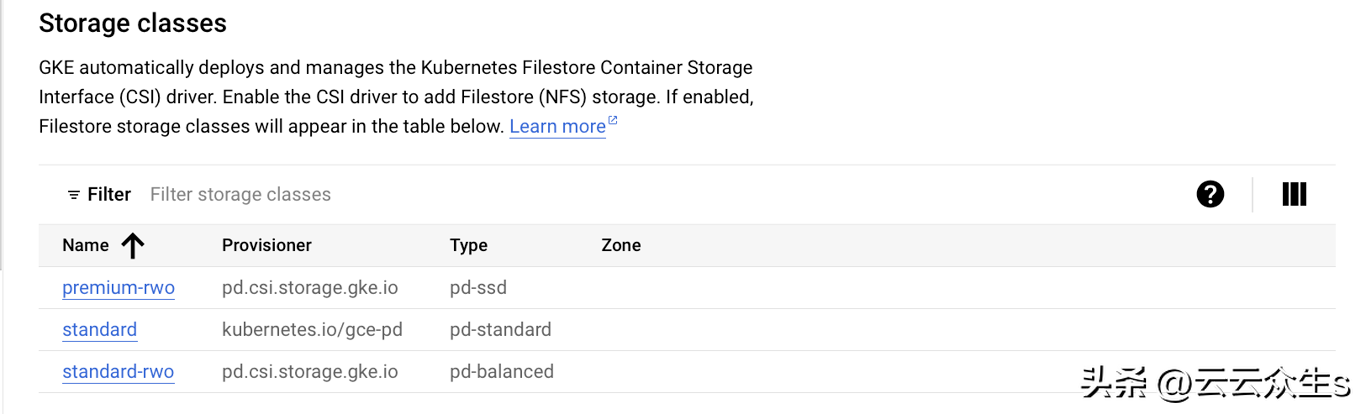
我们删除失败的集群部署:
kub"hippo-ha"
更新清单中的storageClassName为受支持的存储类并应用它。
dataVolumeClaimSpec:storageClassName:standard-rwoaccessModes:-'ReadWriteOnce'resources:requests:storage:1Gi
kubectlapply-npostgres-operator-khigh-availabilityconfigmap//hippo-hacreated
现在我们看到所有的pods都已经正常运行。
kubectl-npostgres-operatorgetpodsNAMEREADYSTATUSRESTARTSAGEhippo-ha-backup-jstq-c8n671/1Running06shippo-ha-pgbouncer-7c467748d-5smt92/2Running031shippo-ha-pgbouncer-7c467748d-6vb7t2/2Running031shippo-ha-pgha1-9s2g-05/5Running032shippo-ha-pgha1-drmv-05/5Running032shippo-ha-repo-host-02/2Running032spgo-6ccdb8b5b-vzzkp1/1Running044m我们成功了!
在这篇博客中,我们成功地识别、诊断和纠正了在Kubernetes中安装Postgres时可能出现的常见问题。我们学会了如何使用Kubernetes的describe函数来获取信息,帮助我们诊断遇到的问题。这里学到的经验不仅适用于Postgres。如果清单不正确或未分配适当的资源,这些问题可能发生在Kubernetes中运行的任何应用程序上。恭喜!您现在拥有解决常见安装问题所需的知识。







