北京时间7月27日凌晨,千呼万唤始出来,StabilityAI发布了模型!
作为新一代文生图模型的正式大版本,是否称得上是全球最强的开源图片生成模型呢?个人觉得可以的!
此前,版本作为研究性质的模型提前发布,看得很多人心痒难耐。0.9的命名,就好像迅雷下载卡在了99%进度条一样,让人难受。

采用了来自StabilityAI的图像控制技术
继之后,StabilityAI发布最强文生图模型
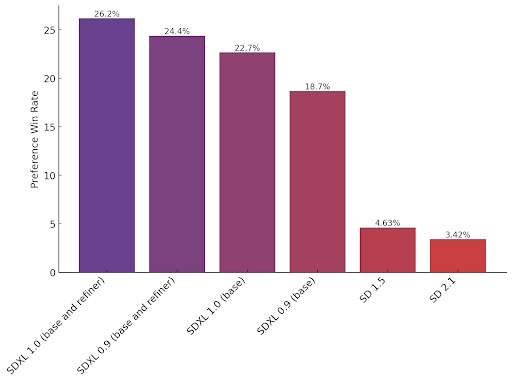
是StabilityAI旗下最强图像生成模型,算是升级版的StableDiffusion,它是目前最强的开源图像生成模型。
更适合复杂抽象概念和设计风格的图像
SDXL几乎可以生成任何艺术风格的高质量图像,即使不写出特定的提示词,也可以生成不同的图像,风格自由度很高。
此外,在色彩鲜艳度和准确度方面有很多调整,对比度、光照和阴影表现都比上一代更好。
值得一提的是,图片分辨率全部采用原生1024x1024分辨率。
此外,SDXL还解决了生成手的难题,还能生成文字,还能描述空间结构信息。
比如,下图有一张描述的是:背景中的女人追逐前景中的狗。

更好的空间控制能力,更强的风格控制能力,更逼真的效果
简洁的语言就能生成高质量图片
现在,SDXL只需几个简单的提示词就能创建复杂、细致、好看的图片。用户不使用"masterpiece"这种提示词就能生成高质量的图像,终于告别冗长的各种起手式了。
此外,SDXL的文本理解能力也上了新台阶,比如,能理解"TheRedSquare"(俄罗斯红场)与"redsquare"(一种形状)等概念之间的区别。

简单的提示词,高质量的输出
最大的开源图像模型
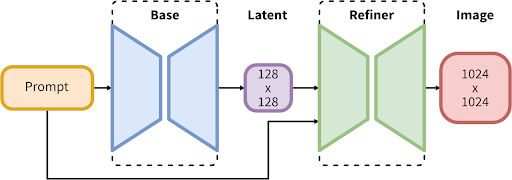
是参数最多的开源图像模型之一,它基于一个全新的架构来构建,由一个包含35亿参数的基础模型和一个66亿参数的精炼器(refiner)组成。
工作流程两步:第一步,基础模型生成带噪声的潜在变量。然后,通过去噪模型进行进一步处理。请注意,基础模型也可以作为一个独立的模块使用。
两步的流程,使得模型可以在不降低速度,计算资源占用较少的情况下稳定地生成图片。
能在有8GB显存的消费级显卡上运行,当然也能在公有云上正常工作。
微调和高级控制
使用,用自己的数据对模型进行微调变得更简单了。生成LoRa或checkpoint需要的数据整理工作更少了。
的时候,最少5张图片就能微调LoRa,现在需要的照片更少了吗?这个可以等大佬出教程,自己试试就知道了。
StabilityAI团队正在构建下一代的面向特定任务的结构、风格和构图控制能力,这是一个专门为SDXL优化的T2I/ControlNet,这部分目前处于测试预览阶段。


现在就想用的话可以试试这几种方式:
第一个,在线通过Clipdrop来访问,这是最简单的。免费用户就得多等几分钟,付费获得更好的优先级,简单试了试,确实很强!
第二个,想自己本地部署的朋友可以在GitHub上下载权重参数,更新AUTOMATIC1111之后,把它跟别的模型放在一起就能直接用。
第三个,开放了API,可以去官网上付费申请使用。
第四个,此外,还可以在AWS的SageMaker和Bedrock上使用。

的License授权使用的是CreativeMLOpenRAIL++-M,没太搞清楚能否能商用。
最后分享我用做的一张图:

Prompt:Arealisticphotoofacyberpunkcatwearingajacket
模型权重参数下载:







